Search the Community
Showing results for tags 'iso'.
Found 3 results
-
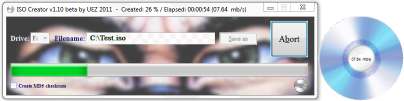
Hi, here a little tool to create ISO files from default ISO 9660 (2048 bytes/sector) CD or DVD format (no audio cd and BD support yet!) Source is too huge for code box -> Look here to have a look to the source code Additional credits to: Ward for MD5 checksum / MemoryDLL routines Harald Vistnes for cd2iso used in v1 and v2 Yashied for WinAPIEx.au3 wolf9228 to play wave from memory AutoItObject Team Download (purely written with AutoIt): ISO Creator v1.16 build 2015-07-13 beta.7z (1110 downloads previously) Thanks to smashly for pointing me to right direction The development of v1 and v2 is discontinued! Download v1: ISO Creator v1.0.0 build 2011-08-03 beta v1.7z (195 downloads previously) Download v2 (everything is called directly from memory): ISO Creator v1.0.0 build 2011-08-03 beta v2.7z (117 downloads previously) Thanks to smartee for the DLL version (experimental) of cd2iso! v1 is using cd2iso.exe to create the ISO v2 is using cd2iso.dll which was created by smartee. For compiled v1, v2 and pure AutoIt versions only (x86) visit (ISO Creator Exe only): 4shared.com or MediaFire You can call ISO Creator.exe also with command line parameters: ISO Creator.exe -s [source cd/dvd drive] -d [filename] (-md5) (-aem) (-exit) -s and -d are mendatory if called from command line! Tested on Win7 x64. If you find any bug please report here! Many thanks to smartee and smashly for their efforts on this project! Br, UEZ Change Log:
-
regex and iso escape sequences Hi, I would like to extract all ISO escape squences embedded in a string and separate them from the rest of the string, still keeping the information about their position, so that, for exemple, a string like this one (or even more complex): (the string could start with normal text or iso sequences) '\u001B[4mUnicorn\u001B[0m' should be 'transformed' in an array like this $a[0] = '\u001B[4m' ; first iso escape sequence $a[1] = 'Unicorn' ; normal text $a[2] = '\u001B[4m' ; second iso escape sequence ... and so on (note: the above escape sequence has 'control codes' marked as "\u001B' for the asc "esc" char for exemple and a similar notation is also used for other control chars, but in the real string to be parsed those control chars are embedded as a single byte with a value from 01 to 31). at this link (http://artscene.textfiles.com/ansi/) there are many example of real ANSI text files . searching on the web I've found some possible solutions that make use of regexp to achieve similar purpose, and above some others, the regexp pattern posted in the following link by kfir (https://stackoverflow.com/questions/14693701/how-can-i-remove-the-ansi-escape-sequences-from-a-string-in-python) seems to be able to catch a wider range of ISO escape sequences (not only color sequences), but my lack of skills on regexp, prevents me from evaluating and testing such patterns I would be very grateful if some regexp guru could come to my rescue... thanks everybody for reading...
-
 Non-important short long story: I was facing several troubles when working with a webservice made in PHP and an AutoIt client. The AutoIt client had to send some data to the PHP webservice, then it would get back part of the data (with additional data) back to AutoIt, then send through Json to another webservice and end up in a TV system (huff). As I was using mostly Inet* functions, working with charsets became complicated, as it had to encode, decode, encode... and the mess is done. On the other end I was receiving a completely buggy string with several problems in accentuated characters (note that I live in Brazil, we speak portuguese that contains a lot of accented chars - Ááãç...). I tried and tried mixing utf_encodes and decodes everywhere, in PHP and Javascript. Wouldn't it be easier if I could just force the string to be UTF-8 and screw everything else? So I found toUTF8() PHP function. I've ported toUTF8() function (truly, the whole Encoding class) by Sebastián Grignoli to AutoIt. It offers useful functions to force a string to be in a specified charset in a really easy way. From the readme file: Usage $utf8_string = toUTF8($utf8_or_latin1_or_mixed_string) $latin1_string = toLatin1($utf8_or_latin1_or_mixed_string) Also: $utf8_string = fixUTF8($garbled_utf8_string) fixUTF8() converts the string to UTF-8 repeatedly until make sure it has only UTF-8 valid chars (it's really UTF-8). Example: #include 'forceutf8.au3' MsgBox(0, '', fixUTF8( 'ãé' ) ) Will output: ãé Note that it's just a port. If you look at both the source codes together (PHP and AutoIt), you'll see that they're exactly the same thing, but in different approaches (PHP arrays converted to Scripting.Dictionary objects, function renames, syntax porting, a few functions completely rewritten due to differences between PHP and AutoIt). Therefore, all credits goes to Sebastián Grignol. It seems that it works only with latin/roman alphabet (used by English). Downloads Download ZIP from Github Wanna help? Fork me on Github
Non-important short long story: I was facing several troubles when working with a webservice made in PHP and an AutoIt client. The AutoIt client had to send some data to the PHP webservice, then it would get back part of the data (with additional data) back to AutoIt, then send through Json to another webservice and end up in a TV system (huff). As I was using mostly Inet* functions, working with charsets became complicated, as it had to encode, decode, encode... and the mess is done. On the other end I was receiving a completely buggy string with several problems in accentuated characters (note that I live in Brazil, we speak portuguese that contains a lot of accented chars - Ááãç...). I tried and tried mixing utf_encodes and decodes everywhere, in PHP and Javascript. Wouldn't it be easier if I could just force the string to be UTF-8 and screw everything else? So I found toUTF8() PHP function. I've ported toUTF8() function (truly, the whole Encoding class) by Sebastián Grignoli to AutoIt. It offers useful functions to force a string to be in a specified charset in a really easy way. From the readme file: Usage $utf8_string = toUTF8($utf8_or_latin1_or_mixed_string) $latin1_string = toLatin1($utf8_or_latin1_or_mixed_string) Also: $utf8_string = fixUTF8($garbled_utf8_string) fixUTF8() converts the string to UTF-8 repeatedly until make sure it has only UTF-8 valid chars (it's really UTF-8). Example: #include 'forceutf8.au3' MsgBox(0, '', fixUTF8( 'ãé' ) ) Will output: ãé Note that it's just a port. If you look at both the source codes together (PHP and AutoIt), you'll see that they're exactly the same thing, but in different approaches (PHP arrays converted to Scripting.Dictionary objects, function renames, syntax porting, a few functions completely rewritten due to differences between PHP and AutoIt). Therefore, all credits goes to Sebastián Grignol. It seems that it works only with latin/roman alphabet (used by English). Downloads Download ZIP from Github Wanna help? Fork me on Github