Search the Community
Showing results for tags 'RegExp'.
-
Hi everyone, I have this string: "main_lot 0x111” & @CRLF & “main_version 0xABC” & @CRLF & “main_number 0xDEAD123” & @CRLF & “main_version 0x333" And I'm trying to extract one specific hexadecimal number, actually main_version from this string by using StringRegExp: How to get 'ABC' from it? I'm not sure if the original string uses @CRLF, @CR or @LF as a line breaks (received from linux over ssh plink.exe) I have tried this code but it doesn't work #include <Array.au3> $sLog = "main_lot 0x111” & @CRLF & “main_version 0xABC” & @CRLF & “main_number 0xDEAD123” & @CRLF & “main_version 0x333" $aVer = StringRegExp($sLog, "main_version\h*(.+)(?:0[xX][[:xdigit:]])", 3) _ArrayDisplay($aVer)
-
Well the plan is to use the power of regular expressions engine of AutoIT for patching binary data. Something like this: StringRegExp( $BinaryData, "(?s)\x55\x8B.." <cut> ... Okay straight to question/problem ... certain bytes that are in the range from 0x80 to 0xA0 won't match. Hmm seem to be a char encoding problem. In detail these are 27 chars: 0x80, 0x82~8C, 0x8E, 0x91~9C, 0x9E,0x9F Here's a small code snippet to explore / explain this problem: #include "StringConstants.au3" $TestData = BinaryToString("0x7E7F808182") ;Okay $match = StringRegExp( $TestData ,'\x7E' ,$STR_REGEXPARRAYFULLMATCH) ConsoleWrite('@extended = ' & @extended & ' $match = ' & $match & @CRLF) ;Okay $match = StringRegExp( $TestData ,'\x7F' ,$STR_REGEXPARRAYFULLMATCH) ConsoleWrite('@extended = ' & @extended & ' $match = ' & $match & @CRLF) ;Error no match $match = StringRegExp( $TestData ,'\x80' ,$STR_REGEXPARRAYFULLMATCH) ConsoleWrite('@extended = ' & @extended & ' $match = ' & $match & @CRLF) ;Okay $match = StringRegExp( $TestData ,'\x81' ,$STR_REGEXPARRAYFULLMATCH) ConsoleWrite('@extended = ' & @extended & ' $match = ' & $match & @CRLF) ;Error no match $match = StringRegExp( $TestData ,'\x82' ,$STR_REGEXPARRAYFULLMATCH) ConsoleWrite('@extended = ' & @extended & ' $match = ' & $match & @CRLF) ;~ output: ;~ @extended = 2 $match = ;~ @extended = 3 $match = ;~ @extended = 0 $match = 1 ;~ @extended = 5 $match = ;~ @extended = 0 $match = 1 Hmm what to do? Go back and use the 'numberstring monster' implementation or just omit that range of 'unsafe bytes'. What is the root of this problem? Any idea how to fix this? Update: Okay I know a byte is not a character. But StringRegExp operates on String and so character level. Okay as long as you stay at Ansi encoding and only use /x00 - /X7F in the search pattern using StringRegExp works well to search for binary data. What bytes can be matched that are in the range from /X7F - /xFF is also depending on the code page. So this avoid to search for bytes in the range from 0x80-0xa0 only applies to Germany. I just change this country setting: to Thai and now near all bytes from /X7F - /xFF fails to match.
-
 Hi, Please help me to change metasymbol line. Right now I have this condition code: If StringInStr($_sName, 'TEXT ') Then $_sName = StringRegExpReplace($_sName, '(^.*)\TEXT (.*)$', '$2') $_sName = StringRegExpReplace($_sName, '(^.*)\ (.*)$', '$1') If Not CheckIsSave_($_sName) Then It work fine with this text file and finds each line which start from 'TEXT': Material B7E671143D244B ==================================== TEXT 2F3139D816C34D 1 TEXT B6A968EF2505A2 1 TEXT 35206697A04F91 1 TEXT EB485AF490D83D 1 TEXT 0DAB42294BD9B3 1 TEXT 3D6525BEE360E1 0 Material D6906B886B06E3 ==================================== TEXT 0CCECCCCFB62AE 1 TEXT 1E14CB29AB43F0 1 TEXT FB7F0DCE9B5950 1 But I have a new text file now the lines of which now are start with 0:, 1: and so on: sm_0 --------------- 0: dummy_gray 1: c_com_socksa_mt 2: c_com_socksa_tn 3: dummy_white 4: default_z 5: dummy_nmap 6: --- 7: --- sm_1 --------------- 0: c_com_prisoner_shoes_di 1: c_com_prisoner_shoes_mt 2: c_com_prisoner_shoes_tn 3: dummy_white 4: default_z 5: c_com_leatherb_rt 6: --- 7: --- how to change (or add) the condition code above to work with new text file? I'm trying to change this script: http://autoit-script.ru/threads/poisk-fajlov-rekursivno-po-dannomu-spisku.26970/post-148646
Hi, Please help me to change metasymbol line. Right now I have this condition code: If StringInStr($_sName, 'TEXT ') Then $_sName = StringRegExpReplace($_sName, '(^.*)\TEXT (.*)$', '$2') $_sName = StringRegExpReplace($_sName, '(^.*)\ (.*)$', '$1') If Not CheckIsSave_($_sName) Then It work fine with this text file and finds each line which start from 'TEXT': Material B7E671143D244B ==================================== TEXT 2F3139D816C34D 1 TEXT B6A968EF2505A2 1 TEXT 35206697A04F91 1 TEXT EB485AF490D83D 1 TEXT 0DAB42294BD9B3 1 TEXT 3D6525BEE360E1 0 Material D6906B886B06E3 ==================================== TEXT 0CCECCCCFB62AE 1 TEXT 1E14CB29AB43F0 1 TEXT FB7F0DCE9B5950 1 But I have a new text file now the lines of which now are start with 0:, 1: and so on: sm_0 --------------- 0: dummy_gray 1: c_com_socksa_mt 2: c_com_socksa_tn 3: dummy_white 4: default_z 5: dummy_nmap 6: --- 7: --- sm_1 --------------- 0: c_com_prisoner_shoes_di 1: c_com_prisoner_shoes_mt 2: c_com_prisoner_shoes_tn 3: dummy_white 4: default_z 5: c_com_leatherb_rt 6: --- 7: --- how to change (or add) the condition code above to work with new text file? I'm trying to change this script: http://autoit-script.ru/threads/poisk-fajlov-rekursivno-po-dannomu-spisku.26970/post-148646 -
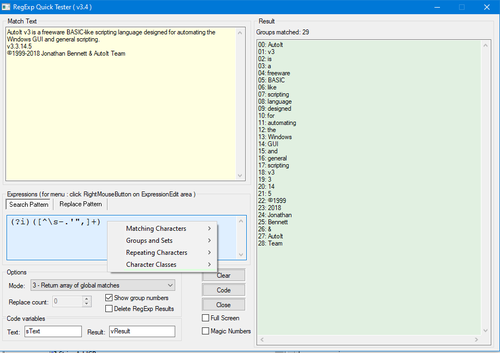
Version 3.6
2,074 downloads
In April 5, 2013 I ask @Lazycat he answer: Then I change this tool a little. Now I back to this and make bigger changed. Here is new version. Update History: = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = 2018/11/07 v3.0 * Changed: AU3Check compilant - mLipok * Changed: almost all Variables renamed - mLipok * Added: "Delete RegExp Results" - mLipok * Added: support for dual monitor - mLipok * Added: "full screen mode" - mLipok = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = 2018/11/08 v3.1 * Added: colors for each Edit control - used GUICtrlSetBkColor() - mLipok * Added: FullScreen option (Checkbox + INI + Remarks in Tip) - mLipok * Added: _IsChecked() - mLipok * Changed: WinMove() - change size of window using: WindowWidth and WindowHeight - mLipok = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = 2018/11/13 v3.2 * Added: If $bFullScreen Then GUICtrlSetFont() - mLipok * Added: WM_COMMAND , $EN_CHANGE - prevent CPU overheat - mLipok = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = 2018/11/29 v3.3 * Changed: $_g_idCheckbox_Clear - also clear $_g_idEdit_Result - mLipok * Changed: ClearResult If GUICtrlRead($_g_idEdit_MatchText) = '' Or GUICtrlRead($_g_idEdit_MatchText) = '' - mLipok * Fixed: prevention CPU overheat - If $iGuiMsg <> 0 Then $_g_bWasAChange = True - any GUI change will fire RegExp result refresh - mLipok * Fixed: Top possition of $_g_idLabel_Dummy control - mLipok * Added: support for TabSwitch - CTRL+TAB and CTRL+SHIFT+TAB - mLipok = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = -
I'm trying to capture everything after a "#ToDo" in my scripts. I got that like this: (?i)[^\v]*#todo(.*) But then I thought it would be nice to use underscores to continue the ToDo... kind of like this: #ToDo: This is a really long explanation about something _ # that is very in-depth and needs to take up a lot of _ # space in a ToDo comment Global $variables = "Bad" I can't seem to capture everything... and maybe I'm trying to do too much with Regex... I keep trying variations of this: Condensed Version: (?im)[^\v]*#todo(?:([^\v]*)_\s*)*#([^\v]*) Expanded with comments (?ixm)(?# Ignore case, ignore newlines in Regex, use multiline option)# [^\v]*(?# Match leading space/s)# \#todo(?# Match the #todo)# (?:([^\v]*)_\s*)*(?# Match lines ending with _)# \#([^\v]*)(?# Last line only, no _'s)# I never seem to be able to build an array well with Regex... I saw something once about not being able to capture repeated patterns, and I think that's my issue
-
Inspired by PHP's preg_split. Split string by a regular expression. Also supports the same flags as the PHP equivalent. v1.0.1 Example: #include "StringRegExpSplit.au3" StringRegExpSplit('splitCamelCaseWords', '(?<=\w)(?=[A-Z])') ; ['split', 'Camel', 'Case', 'Words']
-
Hi guys I need your help. I have string like this : "TDM111A5, RCT222Y5/ 7 ; FDT444E4 /8 , ABC222R5" I need find a coma or semicolon and delete white spaces before and after them The output should be a string and/or array String : "TDM111A5,RCT222Y5/ 7;FDT444E4 /8,ABC222R5" Array: TDM111A5 RCT222Y5/ 7 FDT444E4 /8 ABC222R5
-
 Is there a way to output the regex matches into a file? I have a script to compare two files and check for regex matches. I want to output the matching regex of 'testexample.txt' to another file. #include <MsgBoxConstants.au3> #include <Array.au3> $Read = FileReadToArray("C:\Users\admin\Documents\testexample.txt") $Dictionary = FileReadToArray("C:\Users\admin\Documents\example.txt") For $p = 0 To UBound($Dictionary) - 1 Step 1 $pattern = $Dictionary[$p] For $i = 0 To UBound($Read) - 1 Step 1 $regex = $Read[$i] If StringRegExp($regex, $pattern, 0) Then MsgBox(0, "ResultsPass", "The string is in the file, highlighted strings: " ) Else MsgBox(0, "ResultsFail", "The string isn't in the file.") EndIf Next Next
Is there a way to output the regex matches into a file? I have a script to compare two files and check for regex matches. I want to output the matching regex of 'testexample.txt' to another file. #include <MsgBoxConstants.au3> #include <Array.au3> $Read = FileReadToArray("C:\Users\admin\Documents\testexample.txt") $Dictionary = FileReadToArray("C:\Users\admin\Documents\example.txt") For $p = 0 To UBound($Dictionary) - 1 Step 1 $pattern = $Dictionary[$p] For $i = 0 To UBound($Read) - 1 Step 1 $regex = $Read[$i] If StringRegExp($regex, $pattern, 0) Then MsgBox(0, "ResultsPass", "The string is in the file, highlighted strings: " ) Else MsgBox(0, "ResultsFail", "The string isn't in the file.") EndIf Next Next -
 Im creating a code that will work in this sequence: 1. Copy the text (question) in one atea of the screen 2. Catch the 2 strings (number) 3. Multiply the 2 strings ( $1*$2) 4. Click the next area to put the answer 5. Paste the answer This is my code MouseClick($MOUSE_CLICK_LEFT, 479, 802, 3, 1) ;Clicking all of the text Send("^c") $x = StringRegExpReplace(ClipGet(), 'What is (\d*) x (\d*) \?$', "$1*$2") MouseClick($MOUSE_CLICK_LEFT, 480, 844, 1, 1) ClipPut($x) Send("^v") However the output is this $1*$2 How can I make it solve itself? Because I tried this code: MouseClick($MOUSE_CLICK_LEFT, 479, 802, 3, 1) ;Clicking all of the text Send("^c") MouseClick($MOUSE_CLICK_LEFT, 480, 844, 1, 1) $x = Execute(StringRegExpReplace(ClipGet(), 'What is (\d*) x (\d*) \?$', "$1*$2")) ClipPut($x) Send("^v") Output is just blank text
Im creating a code that will work in this sequence: 1. Copy the text (question) in one atea of the screen 2. Catch the 2 strings (number) 3. Multiply the 2 strings ( $1*$2) 4. Click the next area to put the answer 5. Paste the answer This is my code MouseClick($MOUSE_CLICK_LEFT, 479, 802, 3, 1) ;Clicking all of the text Send("^c") $x = StringRegExpReplace(ClipGet(), 'What is (\d*) x (\d*) \?$', "$1*$2") MouseClick($MOUSE_CLICK_LEFT, 480, 844, 1, 1) ClipPut($x) Send("^v") However the output is this $1*$2 How can I make it solve itself? Because I tried this code: MouseClick($MOUSE_CLICK_LEFT, 479, 802, 3, 1) ;Clicking all of the text Send("^c") MouseClick($MOUSE_CLICK_LEFT, 480, 844, 1, 1) $x = Execute(StringRegExpReplace(ClipGet(), 'What is (\d*) x (\d*) \?$', "$1*$2")) ClipPut($x) Send("^v") Output is just blank text -
argh, pulling my hair out. considering this post: say for a string = "03a", how can I strip out the leading 0 and the a. I have tried: $new = StringRegExpReplace($string, '[^1-9][^0-9]', '') and various combinations: ^0+[^0-9] [^[:digit:]] "[^0].*" "^0*(d+)" I'm going loopy!
-
Hi everyone! After updating autoit, I tried to run an old program using complex regexp's. It did not work. Eventually I broke the problem down to this example: #include <Array.au3> $buf = "First title" & @CRLF & "Tom" & Chr(0x92) & "s sleepwalking" & @CRLF & "Last | line" & @CRLF $items = StringRegExp($buf, '([\x20-\xff]+)\x0d\x0a', 3) _ArrayDisplay($items,'') And this is the result I get when running it: Row 0
-
Hello . How to do that $regexp = starts from "abcdef" and after this could be anything in name WinActivate($regexp)
-
 Text in a file, read into var with fileread: <> <> <> <> < J please look > <> <> <> Hi, I want a RegExp to select around 'please', back to the previous < and forward to the next >. I can select the line of text. Then I add in (?s) and it selects the whole text. I think I want to make it not greedy, (?U) , that seems to make it ungreedy after, but it still selects all the previous lines. $sPattern = "(?s)<.*please.*>" ; 1 $sPattern = "(?s)<(?U).*please.*>" ; 2 $sPattern = "(?s)<(?U).*please(?U).*>" ; 3 $sAry = StringRegExp($sHTML, $sPattern, 3)
Text in a file, read into var with fileread: <> <> <> <> < J please look > <> <> <> Hi, I want a RegExp to select around 'please', back to the previous < and forward to the next >. I can select the line of text. Then I add in (?s) and it selects the whole text. I think I want to make it not greedy, (?U) , that seems to make it ungreedy after, but it still selects all the previous lines. $sPattern = "(?s)<.*please.*>" ; 1 $sPattern = "(?s)<(?U).*please.*>" ; 2 $sPattern = "(?s)<(?U).*please(?U).*>" ; 3 $sAry = StringRegExp($sHTML, $sPattern, 3) -
 I want to rename every new instance of notepad to notepad(random number) If I use WinSetTitle ( "notepad", "", "notepad("&$randomnumber&")" ) this will work pretty good, because if more windows match the search entry it will take the newest. But what if this code runs, but there is no new instance of notepad. It will rename one that was already assigned a number. So I would like to check whether it is already renamed. For example by excluding titles that contain a ")". How do I do that. Read this, but that is pretty confusing: http://stackoverflow.com/questions/406230/regular-expression-to-match-line-that-doesnt-contain-a-word?rq=1
I want to rename every new instance of notepad to notepad(random number) If I use WinSetTitle ( "notepad", "", "notepad("&$randomnumber&")" ) this will work pretty good, because if more windows match the search entry it will take the newest. But what if this code runs, but there is no new instance of notepad. It will rename one that was already assigned a number. So I would like to check whether it is already renamed. For example by excluding titles that contain a ")". How do I do that. Read this, but that is pretty confusing: http://stackoverflow.com/questions/406230/regular-expression-to-match-line-that-doesnt-contain-a-word?rq=1 -
 #include <Array.au3> If @Compiled Then Exit Global Enum $FUNC_OUTER, $FUNC_NAME, $FUNC_PARAM, $FUNC_INNER _Example() Func _Example() Local $sIncludeDir = StringTrimRight(@AutoItExe, StringLen('AutoIt3.exe')) & 'Include\' Local $aOuterArray = _GetFunctionsToArray($sIncludeDir & 'Color.au3') If Not @error Then For $iOuter_idx = 0 To UBound($aOuterArray) - 1 _ArrayDisplay($aOuterArray[$iOuter_idx], ($aOuterArray[$iOuter_idx])[$FUNC_NAME]) Next EndIf EndFunc ;==>_Example Func _GetFunctionsToArray($sUDF_FileFullPath) Local $sUDFContent = FileRead($sUDF_FileFullPath) Local $aResult = StringRegExp($sUDFContent, '(?is)\RFunc (.*?)\((.*?)\)\v\R(.*?)\REndFunc', $STR_REGEXPARRAYGLOBALFULLMATCH) Return SetError(@error, @extended, $aResult) EndFunc ;==>_GetFunctionsToArray
#include <Array.au3> If @Compiled Then Exit Global Enum $FUNC_OUTER, $FUNC_NAME, $FUNC_PARAM, $FUNC_INNER _Example() Func _Example() Local $sIncludeDir = StringTrimRight(@AutoItExe, StringLen('AutoIt3.exe')) & 'Include\' Local $aOuterArray = _GetFunctionsToArray($sIncludeDir & 'Color.au3') If Not @error Then For $iOuter_idx = 0 To UBound($aOuterArray) - 1 _ArrayDisplay($aOuterArray[$iOuter_idx], ($aOuterArray[$iOuter_idx])[$FUNC_NAME]) Next EndIf EndFunc ;==>_Example Func _GetFunctionsToArray($sUDF_FileFullPath) Local $sUDFContent = FileRead($sUDF_FileFullPath) Local $aResult = StringRegExp($sUDFContent, '(?is)\RFunc (.*?)\((.*?)\)\v\R(.*?)\REndFunc', $STR_REGEXPARRAYGLOBALFULLMATCH) Return SetError(@error, @extended, $aResult) EndFunc ;==>_GetFunctionsToArray -
 #include <Array.au3> ; Script Start - Add your code below here Local $test = "<li>One<li>Inner<li>Innermost</li></li></li>" & _ "<li>Two</li> " $loob = StringRegExp($test, '\Q<li>\E(.*?)\Q</li>\E', 3) _ArrayDisplay($loob, "How to return the One... and Two?") Hello, can somebody help me: (1) How can I have the regexp matched the two outermost bullets? Such that: (2) How can I match the "Innermost" bullet? Thanks so much.
#include <Array.au3> ; Script Start - Add your code below here Local $test = "<li>One<li>Inner<li>Innermost</li></li></li>" & _ "<li>Two</li> " $loob = StringRegExp($test, '\Q<li>\E(.*?)\Q</li>\E', 3) _ArrayDisplay($loob, "How to return the One... and Two?") Hello, can somebody help me: (1) How can I have the regexp matched the two outermost bullets? Such that: (2) How can I match the "Innermost" bullet? Thanks so much. -
Hello, Have been thinking about this for a while, so decided to seek for help. I have the following string: "...<tag>1</tag>...<tag>2</tag>...<tag>3</tag>...", which I need to test if all text within <tag> matches certain criteria, e.g. it's a number "\d+". The trick is 1) I need the entire match to fail if only one instance of the text between <tag> doesn't match "\d+"; 2) I need the string to match if there's no <tag>. E.g.: - "...<tag>1</tag>...<tag>2</tag>...<tag>3</tag>..." matches. - "...<tag>a</tag>...<tag>2</tag>...<tag>3</tag>..." fails. - "..." matches. Thanks!
-
Hello, I am trying to create a regExp for following HTML text: <a href="link=1">1</a> <b>2</b> <a href="link=3">3</a> | <a href="link=2">Previous</a> | <a href="link=3">Next</a>My intention is to extract href from last <a> tag. Here is my attempt: Local $reg = '(?i)\|\s?<a href="(.*?)">Next</a>' Local $text = '<a href="link=1">1</a> <b>2</b> <a href="link=3">3</a> | <a href="link=2">Previous</a> | <a href="link=3">Next</a>' $aData = StringRegExp($text,$reg,3) ConsoleWrite($aData[0]&@LF)Now problem is i am unable to extract exact href from the last <a> tag. Here is the output: link=2">Previous</a> | <a href="link=3I know I can use other techniques, but i want to know, why my pattern is not working or what is the right pattern for such situation? Thanks in Advance.
-
Hello, I want to capitalize 1st word of every sentence with StringRegExp, I am able to collect words by using this pattern: Local $reg = '(?:^|(?:[.!?]\s))(\w+)'now my problem is how can I exactly replace these words, e.g. In the following string: I only want to replace 1st "the" of the sentence with "The" but I have only words in array from RegExp, without its position in string. Thanks.
-
Hi I am struggeling around with an RegExp I need to check a string, it should only contain digits and a - This is what i have so far StringRegExp($sColData,"[\s\D]",0)which returns true for every non-digit (\D) character including @CR (which should not exist as well) and whitespaces (\s], but it returns true even if the string contains a - which should return 0 How can i fix that, i want like "match any non-digits and whitespace characters except for a -" ? Best, Thomy
-
Hello, Not sure if I asked the right question but how do I modify the pattern so that it only matches the second test string? $sTest1 = 'bErtrTRtrtXa' $sTest2 = 'ErtrTRtrtX' $sPattern = 'E[A-Za-z]{0,}X' Local $iResult1 = StringRegExp($sTest1, $sPattern) Local $iResult2 = StringRegExp($sTest2, $sPattern) ConsoleWrite('Test 1: ' & $iResult1 & @CRLF & 'Test 2: ' & $iResult2) Thanks!
-
 Hi all, How to get nth line text from a given text with Regexp. For example, i have a text from a window which contains 15 lines. And i need to get the text from 5th line (it may vary). How to do it. I have tried some patters like "(^ &)5" and "[^ $]{5}". But didn't work.
Hi all, How to get nth line text from a given text with Regexp. For example, i have a text from a window which contains 15 lines. And i need to get the text from 5th line (it may vary). How to do it. I have tried some patters like "(^ &)5" and "[^ $]{5}". But didn't work. -
Hi all, How to find first and last word in a sentence with Regular expression ?. Sentence is the code from SciTE. For example if sentence is; "For $i = 0 to 15" I need to extract "For from the sentence And the same way i need last word from a sentence "If Apple = 15 Then" I need "Then" from the sentence.
-
 I have constants A and B and C, in fact they are not one char but whole word and they can be included at the end of test text in parenthesis there can be only one of them but also two of them or all three separated by coma in any order (A) or (A,B ) or (C,A) or (A,B,C) or (A,C,B ) ... I need to get text in these parenthesis ; in comment at end of each line is what I want to get Test1('some text') ; '' Test1('some text (something)') ; '' Test1('some (something) text') ; '' --> ignore other () not at the end Test1('some (something) (A) text') ; '' --> I want only at end of string Test1('some (something) text (A)') ; 'A' Test1('some text (A)') ; A Test1('some text (B)') ; B Test1('some text (A,B,C)') ; 'A,B,C' Test1('some text (A,C,B)') ; 'A,C,B' Test1('some text (A,C,X)') ; 'A,C' --> not X Test1('some text (ABC)') ; '' --> missing , Func Test1($text) $regexp = '.*? \(([A|B|C])\)' $ret = StringRegExpReplace($text, $regexp, '$1') ConsoleWrite('regexp: ' & $regexp & ' text: ' & $text & ' --> ' & $ret & @CRLF) $regexp = '\z\(([A|B|C])\)' $ret = StringRegExpReplace($text, $regexp, '$1') ConsoleWrite('regexp: ' & $regexp & ' text: ' & $text & ' --> ' & $ret & @CRLF) $regexp = '\z\(([A|B|C]{1,3})\)' $ret = StringRegExpReplace($text, $regexp, '$1') ConsoleWrite('regexp: ' & $regexp & ' text: ' & $text & ' --> ' & $ret & @CRLF) $regexp = '\z\(([A|B|C|,]{1,3})\)' $ret = StringRegExpReplace($text, $regexp, '$1') ConsoleWrite('regexp: ' & $regexp & ' text: ' & $text & ' --> ' & $ret & @CRLF) $regexp = '.*?\(([A|B|C]{1,3})\)' $ret = StringRegExp($text, $regexp, 3) If Not @error Then $ret = $ret[0] Else $ret = '' EndIf ConsoleWrite('not replace: regexp: ' & $regexp & ' text: ' & $text & ' --> ' & $ret & @CRLF) ConsoleWrite(@CRLF) EndFunc I don't know how to use z (at end of string) and how to incorporate coma separator into my RegExp expression these my RexExp expressions are not working even for simple one value In function Test1() should be only one correct RexExp but I have there more because I want to show some of my attempts. EDIT: fixed mistake in last RegExp I hope that for RegExp gurus this will be very easy :-)
I have constants A and B and C, in fact they are not one char but whole word and they can be included at the end of test text in parenthesis there can be only one of them but also two of them or all three separated by coma in any order (A) or (A,B ) or (C,A) or (A,B,C) or (A,C,B ) ... I need to get text in these parenthesis ; in comment at end of each line is what I want to get Test1('some text') ; '' Test1('some text (something)') ; '' Test1('some (something) text') ; '' --> ignore other () not at the end Test1('some (something) (A) text') ; '' --> I want only at end of string Test1('some (something) text (A)') ; 'A' Test1('some text (A)') ; A Test1('some text (B)') ; B Test1('some text (A,B,C)') ; 'A,B,C' Test1('some text (A,C,B)') ; 'A,C,B' Test1('some text (A,C,X)') ; 'A,C' --> not X Test1('some text (ABC)') ; '' --> missing , Func Test1($text) $regexp = '.*? \(([A|B|C])\)' $ret = StringRegExpReplace($text, $regexp, '$1') ConsoleWrite('regexp: ' & $regexp & ' text: ' & $text & ' --> ' & $ret & @CRLF) $regexp = '\z\(([A|B|C])\)' $ret = StringRegExpReplace($text, $regexp, '$1') ConsoleWrite('regexp: ' & $regexp & ' text: ' & $text & ' --> ' & $ret & @CRLF) $regexp = '\z\(([A|B|C]{1,3})\)' $ret = StringRegExpReplace($text, $regexp, '$1') ConsoleWrite('regexp: ' & $regexp & ' text: ' & $text & ' --> ' & $ret & @CRLF) $regexp = '\z\(([A|B|C|,]{1,3})\)' $ret = StringRegExpReplace($text, $regexp, '$1') ConsoleWrite('regexp: ' & $regexp & ' text: ' & $text & ' --> ' & $ret & @CRLF) $regexp = '.*?\(([A|B|C]{1,3})\)' $ret = StringRegExp($text, $regexp, 3) If Not @error Then $ret = $ret[0] Else $ret = '' EndIf ConsoleWrite('not replace: regexp: ' & $regexp & ' text: ' & $text & ' --> ' & $ret & @CRLF) ConsoleWrite(@CRLF) EndFunc I don't know how to use z (at end of string) and how to incorporate coma separator into my RegExp expression these my RexExp expressions are not working even for simple one value In function Test1() should be only one correct RexExp but I have there more because I want to show some of my attempts. EDIT: fixed mistake in last RegExp I hope that for RegExp gurus this will be very easy :-) -
I'm doing parsing of HTML file with <table>. I need to go through rows and columns of table, ideally to get two dimensional array. I use this way with simple two levels of calling StrinRegExp() for rows and columns: ;~ $html = FileRead('table.html') $html = '<tr><td>r1c1</td> <td>r1c2</td></tr> <tr><td>r2c1</td> <td>r2c2</td></tr> <tr><td>r3c1</td> <td>r3c2</td></tr>' $rows = StringRegExp($html, '(?s)(?i)<tr>(.*?)</tr>', 3) For $i = 0 to UBound($rows) - 1 $row = $rows[$i] ConsoleWrite("Row " & $i & ': ' & $row & @CRLF) $cols = StringRegExp($row, '(?s)(?i)<td>(.*?)</td>', 3) For $j = 0 to UBound($cols) - 1 $col = $cols[$j] ConsoleWrite(" Col " & $j & ': ' & $col & @CRLF) Next Next Output: In my example there is called StringRegExp() for each row of table which is ineffective for many rows. It works fine, but my question is if there is better and more effective approach, maybe some clever the only one RegExp pattern? Or maybe using StringRegExp with option=4? I 'm not experienced with this option (array in array) and example in helpfile is not very clear to me so I don't know if this option=4 can be used also for HTML table parsing.










