Leaderboard



Popular Content
Showing content with the highest reputation on 01/22/2021 in all areas
-

manipulate large csv-file
FrancescoDiMuro reacted to TheXman for a topic
@dejhost FYI, Because you're dealing with such large datasets, it is easy to miss some of the details & data if you aren't careful. For example, in the sample JSON file that you provided, there are 2 images that don't have any .Label object information. Therefore, those 2 records did not show up in the CSV data. If that's what was expected, then all is good. If you expected to see all images, whether they had object information or not, then those types of records would need to be taken into account. So if you noticed and were wondering why you were missing some of the input images in the CSV data, that's why. The 2 JSON objects without label object information: { "ID": "ckjayp5lc00003a69wakzxsxg", "DataRow ID": "ckj9odjg37bi20rh6ei442ug7", "Labeled Data": "https://storage.labelbox.com/ckj9o1nvf6pqk0716vn24noz7%2F0bacdc01-bee2-3b16-627e-671b8f6c2a1a-DSC04905.jpg?Expires=1611474714892&KeyName=labelbox-assets-key-1&Signature=dvsZdXT3dbUeRBvORvVxtMhhyMA", "Label": {}, "Created By": "victor@oasisoutsourcing.co.ke", "Project Name": "SubSeaScanning", "Created At": "2020-12-30T05:11:30.000Z", "Updated At": "2020-12-30T05:23:05.000Z", "Seconds to Label": 32.094, "External ID": "DSC04905.jpg", "Agreement": -1, "Benchmark Agreement": -1, "Benchmark ID": null, "Dataset Name": "Trial", "Reviews": [ { "score": 1, "id": "ckjc8j0k60gk50yaw07n69wiu", "createdAt": "2020-12-31T02:34:25.000Z", "createdBy": "victor@oasisoutsourcing.co.ke" } ], "View Label": "https://editor.labelbox.com?project=ckj9obfp954gq0718tasdrinc&label=ckjayp5lc00003a69wakzxsxg" } { "ID": "ckjmlilco000039686bfxpf8k", "DataRow ID": "ckjm8xorhfbe80rj53hi0bg36", "Labeled Data": "https://storage.labelbox.com/ckj9o1nvf6pqk0716vn24noz7%2F4644e43b-5e58-ff51-d1e3-4551ed722d6f-n101_0408.jpg?Expires=1611474715610&KeyName=labelbox-assets-key-1&Signature=erTXaMYyBO56kurONJv6AVGt8zU", "Label": {}, "Created By": "evans@oasisoutsourcing.co.ke", "Project Name": "SubSeaScanning", "Created At": "2021-01-07T08:31:15.000Z", "Updated At": "2021-01-07T08:31:16.000Z", "Seconds to Label": 219.925, "External ID": "n101_0408.jpg", "Agreement": -1, "Benchmark Agreement": -1, "Benchmark ID": null, "Dataset Name": "Aassgard Spool - Batch 1", "Reviews": [ { "score": 1, "id": "ckjn49ska0p010yd17ws9eyyh", "createdAt": "2021-01-07T17:20:44.000Z", "createdBy": "victor@oasisoutsourcing.co.ke" } ], "View Label": "https://editor.labelbox.com?project=ckj9obfp954gq0718tasdrinc&label=ckjmlilco000039686bfxpf8k" }1 point -
If you want to copy all types of files in a single copy, you could use robocopy (robust copy) : #include <Constants.au3> #include <WinAPIConv.au3> $iPID = Run(@ComSpec & ' /c robocopy "c:\apps\temp" "c:\apps\back" *.PDF *.DXF /s /v', "", @SW_HIDE, $STDOUT_CHILD) ProcessWaitClose($iPID) $sText = StdoutRead($iPID) ConsoleWrite (_WinAPI_OemToChar($sText) & @CRLF) You can get a full report of the job and save it if you want...1 point
-
KindEbook Wishlist has been updated to v8.1. See Post #2 on Page 1 for download. MAJOR BUGFIX. (v8.1) BUGFIX for retrieving Summary and Prices from file. Bugfix for Publication Date. Bugfix for Kobo Price comparison decimal issue. NOTE - Had to re-upload after fixing another bug which crashed the program ... damn bugs. When adding the new Kobo code I overlooked the impact of the leeway variable being added to current price and making the decimal disappear, which another section of code didn't take too kindly too ... my fault again for not doing an array check for the existence of the second element ... oops.1 point
-
manipulate large csv-file
FrancescoDiMuro reacted to TheXman for a topic
Thanks! I updated my previous post with a commented description of what the jq filter does just in case anyone else, that comes across this topic, may be interested in jq and how it can be used to process JSON.1 point -
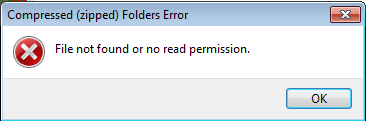
See previous post for other new updates today. Batch Ebook Convert has been updated to v3.8. See Post #3 on Page 3 for download. (v3.8) Implemented a manual select (once off) KFXInput CLI option for the selected ebook, found on the Program Options window, and useful where an error reports the need to use such for converting. (v3.7) Another Bugfix attempt for the rare zipping error, involving modifying the Zip UDF. (v3.6) Another Bugfix attempt for the rare zipping error, also involving modifying the Zip UDF in an effort to catch the error and not remain trapped in a perpetual program loop. If the fix fails to work (program stays trapped), then on restart the program will hopefully prompt to process the missing Log file records, plus also deal with left over files etc when conversion resumed. NOTE - The elusive error may be timing related, so to that end there is now also a 2 second delay between the ebook being extracted to a HTML folder, and the zipping of that folder. This error may also be a permission issue as reported by the error message, perhaps AV related (in which case, the delay may need increasing). EDIT This is the error that pops up. And this is despite my code detecting it does exist, and so I am guessing it is some kind of permission issue ... or a bug ... not forgetting I can at times convert many many ebooks in the same way without getting this error ... and size or file count has no bearing ... so an elusive one indeed.
 1 point
1 point -
Okay, time for those updates. KindEbook Wishlist v8.0 - See Post #2 on Page 1 for download. UpdateFromOPF v7.5 - See Post #5 on Page 1 for download. AZWPlug v6.8 - See Post #3 on Page 1 for download. Add Book & All Formats To Calibre v5.0 - See Post #4 on Page 1 for download. Bucket-for-URLs v2.2 - See Post #17 on Page 1 for download. Lots of improvements. My apologies for the skipped updates ... no doubt due to a variety of reasons/distractions/etc. KindEbook Wishlist update was a priority for the last few days due to crashing on adding a new ebook to the list. The crash was my fault, but also due to a recent change by Amazon. I have now added the (overlooked) array count check to avoid the crash, as well as code to cater for the new change by Amazon.1 point
-
Here's an example that uses the jq UDF to generate CSV data from the JSON file attached in one of the previous posts. It generates the 52,405 CSV records in less than 2 seconds on my laptop. The CSV contains the data items that were circled in red in the post above. If you want TSV data instead of CSV data, just change the @csv to @tsv in $JQ_FILTER. #cs This example uses the jq UDF. https://www.autoitscript.com/forum/files/file/502-jq-udf-a-powerful-flexible-json-processor/ #ce #include <Constants.au3> #include "jq.au3" ;<== Modify as needed _jqInit("jq-win64.exe") ;<== Modify as needed If @error Then Exit MsgBox($MB_ICONERROR + $MB_TOPMOST, "ERROR", StringFormat("ERROR: Unable to initialize jq - @error = %s", @error)) example() Func example() Const $JSON_FILE = "export-2021-01-10T07_51_53.836Z.json" ;<== Modify as needed Const $JQ_FILTER = '.[] | ' & _ '{file: ."External ID", type: .Label.objects[]?} | ' & _ '{file, value: .type.value, top: .type.bbox.top, left: .type.bbox.left, height: .type.bbox.height, width: .type.bbox.width} | ' & _ '[.[]] | @csv' Local $hTimer = TimerInit() Local $sCmdOutput = _jqExecFile($JSON_FILE, $JQ_FILTER) Local $iTimerDiff = TimerDiff($hTimer) write_log_line(@CRLF & "================================") write_log_line($sCmdOutput) write_log_line(@CRLF & "Duration: " & StringFormat("%.3f seconds", $iTimerDiff / 1000)) EndFunc Func write_log_line($sMsg = "") Const $TITLE_NOTEPAD = "[RegExpTitle:(?i)untitled - notepad]" Static $hWndNotepad = -1 ;If we don't have a handle to notepad yet If $hWndNotepad = -1 Then ;If there isn't an existing instance of notepad running, launch one If Not WinExists($TITLE_NOTEPAD) Then Run("Notepad.exe") ;Get handle to notepad window $hWndNotepad = WinWait($TITLE_NOTEPAD, "", 3) If Not $hWndNotepad Then Exit MsgBox($MB_ICONERROR, "ERROR", "Unable to find Notepad window.") EndIf ;Paste msg to notepad text If WinExists($hWndNotepad) Then ControlCommand($hWndNotepad, "", "Edit1", "EditPaste", $sMsg & @CRLF) EndIf EndFunc Snippet of the output: "n101_0058.jpg","ocluded_ucoded_target",803,0,24,20 "n101_0058.jpg","ocluded_coded_target",845,0,57,53 "n101_0058.jpg","uncoded_target",1007,66,32,38 "n101_0058.jpg","coded_target",1051,72,58,65 "n101_0058.jpg","uncoded_target",1213,145,30,38 . . . "n101_0252.jpg","uncoded_target",2377,4194,40,54 "n101_0252.jpg","uncoded_target",2651,3126,40,48 "n101_0252.jpg","uncoded_target",2013,3421,31,47 "n101_0252.jpg","coded_target",2054,3224,54,75 "n101_0252.jpg","uncoded_target",2084,3170,33,42 Duration: 1.279 seconds For anyone reading this later who's interested in understanding the jq filter that was used, here's the filter with comments. FYI, this filter can also be fed to the jqExec* functions as a file, instead of as a string literal, using the -f option. The "|" symbol basically tells the processor to feed the result of the previous part to the next part. # For each top-level array entry .[] | # Reduce to only interesting json objects/data, # creating an object for each .Label.objects' array # object { file: ."External ID", label: .Label.objects[]? } | # Reduce result to final set of objects with data of interest { file, value: .label.value, top: .label.bbox.top, left: .label.bbox.left, height: .label.bbox.height, width: .label.bbox.width } | # Convert result to an array for input to @csv [.[]] | # Convert array to CSV @csv1 point
