Leaderboard



Popular Content
Showing content with the highest reputation on 06/12/2020 in all areas
-
Yeah, MVP is a wonderful forum member, very versatile, but with one extremely annoying habit: he keeps changing his avatar.3 points
-

Windows issues after running script
argumentum reacted to DaSInC for a topic
Dude - THANK YOU! It was so simple, when you know what to look for! Mate, it is 2:00am here and I can finally go to bed! Legend.1 point -
Maybe this will help: https://www.autoitscript.com/wiki/FAQ#Why_does_the_Ctrl_key_get_stuck_down_after_I_run_my_script.3F1 point
-

A cross-platform implementation of the AutoIt language
seadoggie01 reacted to TheDcoder for a topic
You don't have to, working with code doesn't mean only writing low-level C code, there are many other things which can be worked on... such as writing scripts and documentation1 point -
Hello. I get the issue using AutoIt 3.3.14.5 No issue using Beta AutoIt 3.3.15.1 Try using Beta and check if you get the issue. Saludos1 point
-
I'd call that cross-dressing or cross referencing at the crossroads of good cross-platform implementation ... if you get what I mean. At least you're not working at cross-purposes or crossing over. Keep up the good work.1 point
-
A cross-platform implementation of the AutoIt language
argumentum reacted to TheDcoder for a topic
@argumentum Those are some very interesting insights, thanks for bringing them up For now I would like to keep it simple, and not try to overly optimize... we can do that once we have the basics working I may or may not change the default chunk size to 8 KB, as it seems to ideal when taking the block sizes of the HDD into account. We are looking at memory vs. disk speed trade-off here, and I imagine the difference would be minuscule practically. The most important part, having an efficient "algorithm", is done. There is only one more method which is better, that is to use platform-native API to query the file size and then read all of that at once, no chunks The current code is a good balance of efficiency combined with portability as everything is written in standard C.1 point -

A cross-platform implementation of the AutoIt language
TheDcoder reacted to argumentum for a topic
if you're gonna read from the disk then, what is the cluster. You're gonna find that 4 k is becoming standard. Should optimize for bigger and faster hardware. Memory is abound. But like everything else, try different values and build a table of results. You may find that is standard may very well be based in old solutions for old hardware. In any case the OS will read ahead so no big deal. But if the slowest part is reading from spinning rust ( HDD ), the best is to optimize that. The rest of the function is CPU and memory and that is not a bottle neck. Try and see. Try in old hardware and the newest you can get. And since I have no experience with what I'm presenting, I hope to not have wasted you time or worse, mislead you. Edit: from https://stackoverflow.com/questions/10698339/what-would-be-an-ideal-buffer-size Optimum buffer size is related to a number of things: file system block size, CPU cache size and cache latency. Most file systems are configured to use block sizes of 4096 or 8192. In theory, if you configure your buffer size so you are reading a few bytes more than the disk block, the operations with the file system can be extremely inefficient (i.e. if you configured your buffer to read 4100 bytes at a time, each read would require 2 block reads by the file system). If the blocks are already in cache, then you wind up paying the price of RAM -> L3/L2 cache latency. If you are unlucky and the blocks are not in cache yet, the you pay the price of the disk->RAM latency as well. This is why you see most buffers sized as a power of 2, and generally larger than (or equal to) the disk block size. This means that one of your stream reads could result in multiple disk block reads - but those reads will always use a full block - no wasted reads. ..that sounds better than my writing1 point -
Alright, I finished work on the readfile function, looks pretty solid to me /* * MIT License * * Copyright (c) 2020 Damon Harris <TheDcoder@protonmail.com> * * Permission is hereby granted, free of charge, to any person obtaining a copy * of this software and associated documentation files (the "Software"), to deal * in the Software without restriction, including without limitation the rights * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell * copies of the Software, and to permit persons to whom the Software is * furnished to do so, subject to the following conditions: * * The above copyright notice and this permission notice shall be included in all * copies or substantial portions of the Software. * * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE * SOFTWARE. */ #ifndef READ_FILE_BUFFER_SIZE #define READ_FILE_BUFFER_SIZE 1024 #endif struct ReadFileBufferNode { char buffer[READ_FILE_BUFFER_SIZE]; size_t data_len; struct ReadFileBufferNode *next; }; /// @brief Read the contents of a text file into a dynamically allocated buffer efficiently /// @details This function reads the file in chunks which are stored in a linked list, and then all of the chunks are concatenated /// into a single buffer which perfectly fits the whole string. /// @author Damon Harris (TheDcoder@protonmail.com) /// @param [in] file Pointer to the FILE to read. /// @returns If success, pointer to dynamically allocated buffer containing the full contents of the file, NULL otherwise in case of an error. char *readfile(FILE *file) { // Define the final buffer char *final_buffer = NULL; size_t final_size = 0; // Define and allocate the initial node struct ReadFileBufferNode *initial_node = malloc(sizeof(struct ReadFileBufferNode)); if (!initial_node) return NULL; // Read the contents of file in chunks struct ReadFileBufferNode *curr_node = initial_node; struct ReadFileBufferNode *next_node; while (true) { // Copy the current chunk size_t bytes_read = fread(curr_node->buffer, 1, READ_FILE_BUFFER_SIZE, file); curr_node->data_len = bytes_read; final_size += bytes_read; if (bytes_read < READ_FILE_BUFFER_SIZE) { // Check if we have an error if (ferror(file)) goto cleanup; // Mark this node as final curr_node->next = NULL; // Break the loop break; } // Allocate the next buffer node next_node = malloc(sizeof(struct ReadFileBufferNode)); if (!next_node) goto cleanup; curr_node->next = next_node; curr_node = next_node; } // Allocate the buffer final_buffer = malloc(final_size + 1); if (!final_buffer) goto cleanup; final_buffer[final_size] = '\0'; // Copy data into the final buffer curr_node = initial_node; char *curr_chunk = final_buffer; do { memcpy(curr_chunk, curr_node->buffer, curr_node->data_len); curr_chunk += curr_node->data_len; curr_node = curr_node->next; } while (curr_node); // Free all nodes cleanup: curr_node = initial_node; do { next_node = curr_node->next; free(curr_node); curr_node = next_node; } while (curr_node); // Return the final buffer return final_buffer; } I can now *finally* begin work on the parser, will do that later today1 point
-

Where is @ScriptLineNumber
zeenmakr reacted to HurleyShanabarger for a topic
I am using this with @error: #NoTrayIcon #Region ;**** Directives created by AutoIt3Wrapper_GUI **** #Tidy_Parameters=/reel /sf /ri #EndRegion ;**** Directives created by AutoIt3Wrapper_GUI **** #Region Variables/Opt Global Const $DEBUG = True #EndRegion Variables/Opt #Region Main _Main() Func _Main() SetError(0xDEAD) _LogError() EndFunc ;==>_Main #EndRegion Main #Region Functions Func _LogError($p_iERR = @error, $p_iSLN = @ScriptLineNumber) If Not $p_iERR Then Return If Not $DEBUG Then Return ConsoleWrite("Error: 0x" & Hex($p_iERR, 4) & " @SLN " & $p_iSLN & @CRLF) EndFunc ;==>_LogError #EndRegion Functions1 point -
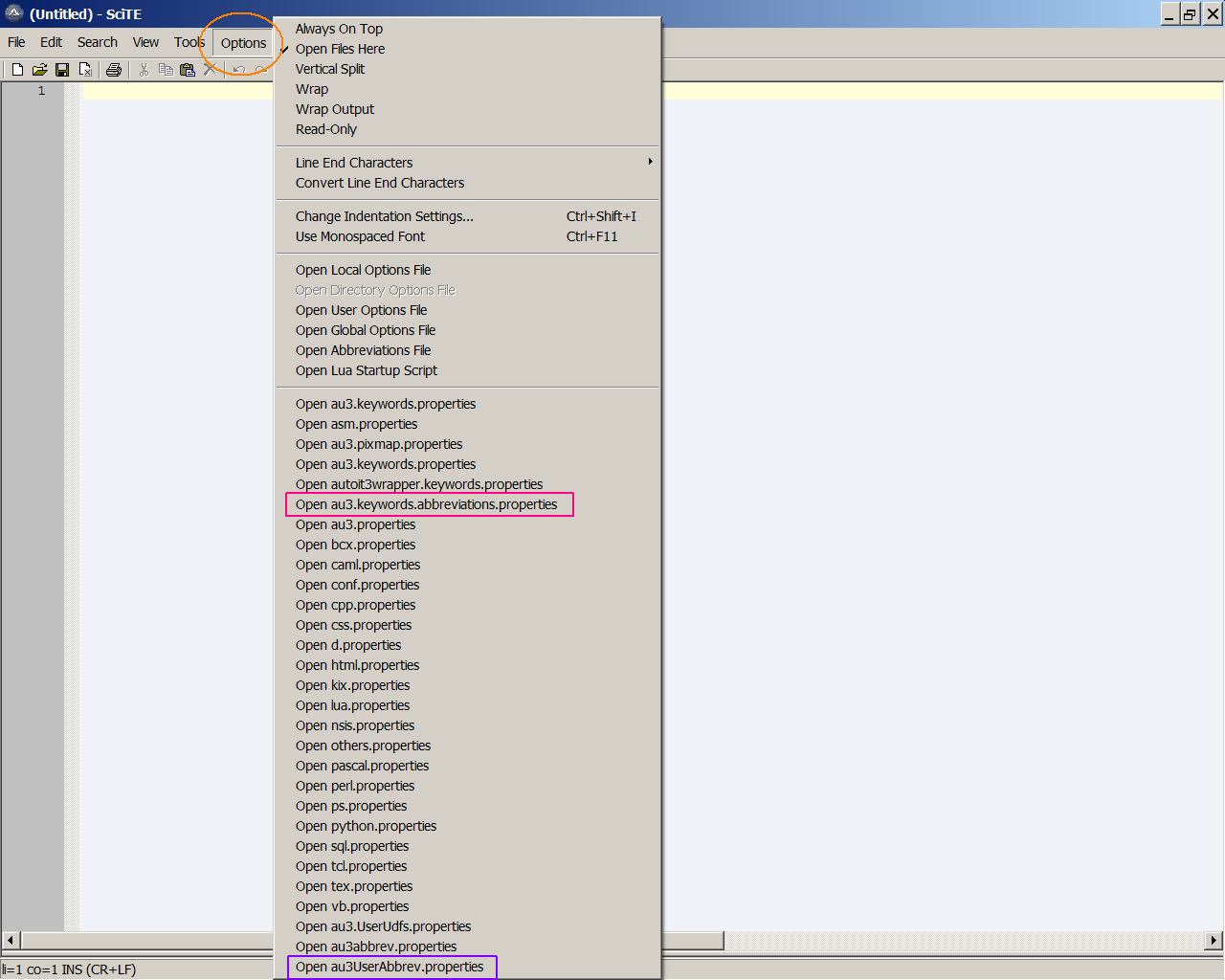
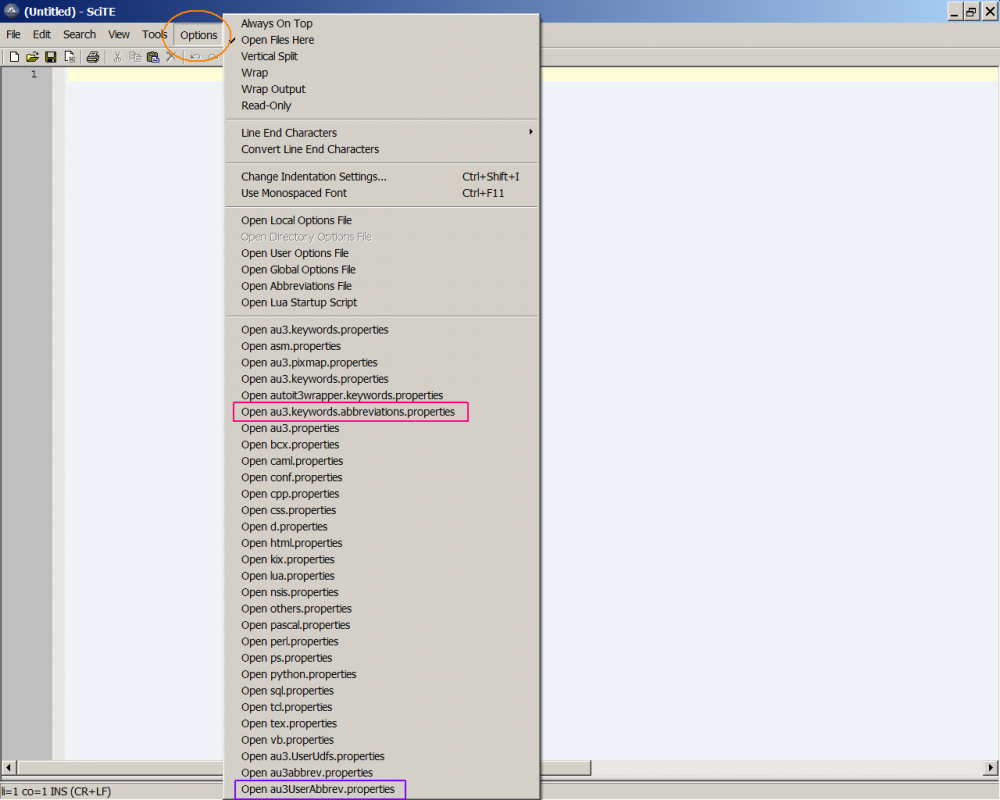
1. Full Version of SciTE : The download page simply says : AutoIt Script Editor (Customised version of SciTE with lots of additional coding tools for AutoIt) - Installer containing SciTE and all configuration files plus utilities I would definitely prefer the Full Version, because it provides many new features. Just Download and install it (you can probably use the Portable Version, but I haven't done that yet) 2. Add an abbreviation (my way ) : Open the SciTE-Editor (Full Version). Here again the proceeding (open spoiler with graphic) -> Click on Options -> Choose Open au3.keywords.abbreviations.properties ==> add sln -> Save -> Choose Open au3UserAbbrev.properties ==> add (and save after) : sln=@ScriptLineNumber | Of course you can also use the Abbreviation Manager (see posting by @careca ) if you feel more comfortable with it - that's a matter of personal preference. Once you understand how the abbreviations work, you can integrate e.g. entire structures. This can save a lot of unnecessary typework.
 1 point
1 point -
The advantages are "A lot" and just use the installer when you have used the AutoIt3 installer as well. Install the Full version first and then start trying all of this, because else you will get issues like this! Jos1 point
-

Button over Pic control
msgladiator reacted to dabien99 for a topic
To answer my own question, all I needed to do was change the state of the Picture control to disabled, by using the GUICtrlSetState function (setting the state of that control to $GUI_DISABLE) Thanks Martin!1 point